Как удалить дубли с сайта
Вы знаете, что на любом сайте можно найти дубли? Конечно, если их никто до этого не поборол. Вот именно сейчас я и расскажу, как их удалить раз и… ненавсегда, конечно, так как появляются новые и новые. Этот вопрос нужно постоянно контролировать. Своевременная реакция на существующие дубликаты, а также предотвращение новых окупится, поверьте.
Немного резюме (“В предыдущих сериях” ): мы уже узнали о видах дублей и их примерах, о том, чем же они угражают сайту; о том, как найти дубликаты, которые, конечно же, не хотят быть найденными. Они хотят натравить на вас Google Panda.
Все последствия дублированного контента понятны, но от этого совсем не легче. Значит, нужно бороться и брать контроль над индексацией сайта в свои руки.
Методы борьбы с внутренними дубликатами
Это простое удаление страницы-дубликата. Подойдет этот метод только в том случае, если страница не несет никакой пользы для посетителей сайта. Дополнительно можно удалить эту страницу из индекса в Вебмастере Google. Важно, чтобы никакие другие страницы сайта не ссылались на удаленную, а то робот снова и снова будет пытаться ее проиндексировать и исправно выдавать ошибку индексации в Вебмастере, а на сайте – 404 (404 страницу еще нужно красиво оформить). Если все сделано правильно – через некоторое время страница канет в Лету.
Он означает, что страница перемещена навсегда (в отличие, от 302, когда страница перемещается временно). 301 редирект подходит, если страница-дулибкат не совсем уж бесполезная, а наоборот – приносит трафик и имеет обратные ссылки. Он передает вес с одной страницы на другую. Но вопреки распространенному заблуждению, вес передается не полностью, какая-то его часть все же теряется. Прописать 301 редирект можно в файле .htaccess, в общем виде он будет таким:
RedirectPermanent /old-page https://site.ru/new-page/
301 редирект подходит не только для того, чтобы справиться с дублированным контентом, но еще и с временными страницами (например, страницами акций на сайте, которые не хранятся в архивах, а просто удаляются и выдают 404 ошибку), которые снова же могут иметь обратные ссылки. Такие страницы лучше перенаправлять на другие наиболее релевантные страницы сайта. Если таковых нет – можно и на главную.
С 2009 года Google, а позже и Яндекс ввел этот тег. Он указывает поисковым роботам, какая из 2 и более страниц должна ранжироваться. Каноникл прописывается в теге <head> каждой из страниц, для которых он применяется. Выглядит он так:
<link rel="canonical" href="https://vash-site/kanon" />
Важно, чтобы каждая из канонизируемых страниц (т.е. на которой прописан тег rel=canonical), указывала на одну и ту же страницу (которая и будет ранжироваться), но ни в коем случае не на себя саму, а то потеряется весь смысл. Когда робот приходит на страницу с тегом rel=сanonical, он как бы присоединяет эту страницу к той, что указана в тэге, склеивает их. Таким образом, если вы наберете в Гугле cache:site.ru/stranitsa-dublicat, а кэш увидите для site.ru/kanon – вы все сделали правильно.
Страницы-дубликаты можно запретить и в файле robots.txt. Таким образом, они не будут индексироваться поисковыми роботами, но будут доступны на сайте.
Отсюда вывод: лучше всего запрещать «неугодные» страницы заранее и делать это осторожно.
Контролировать индексацию сайта можно и с помощью meta robots: INDEX/NOINDEX и FOLLOW/NOFOLLOW. Обычно по умолчанию для каждой страницы стоит INDEX, FOLLOW, что означает: страница индексируется и робот проходит по ссылкам с нее. Чтобы избавиться от страницы-дубликата, можно заключить ее в теги NOINDEX,NOFOLLOW (страница не индексируется, и робот не проходит по ссылкам с нее), но еще лучше – NOINDEX, FOLLOW (страница не индексируется, но робот проходит по расположенным на ней ссылкам).
В WordPress существует специальный плагин – WordPress Meta Robots – он поможет настроить meta robots для каждой страницы или записи.
Заключение страницы в теги NOINDEX, FOLLOW хорошо подойдет для страниц с нумерацией (это один из способов борьбы с дублями на них).
Этот инструмент удаления страниц находится в Вебмастере> Конфигурация сайта> Доступ робота> Удалить URL. Этим инструментом нужно пользоваться в последнюю очередь и лучше в совокупности с другими мерами. Основанием для удаления страниц (для Гугла) может послужить несколько вещей: если страницы выдают 404 ошибку, если они запрещена в robots.txt или с помощью meta robots. Если же страницы нигде не запрещены, Гугл, конечно удалит их, если вы попросите, но всего на 90 дней.
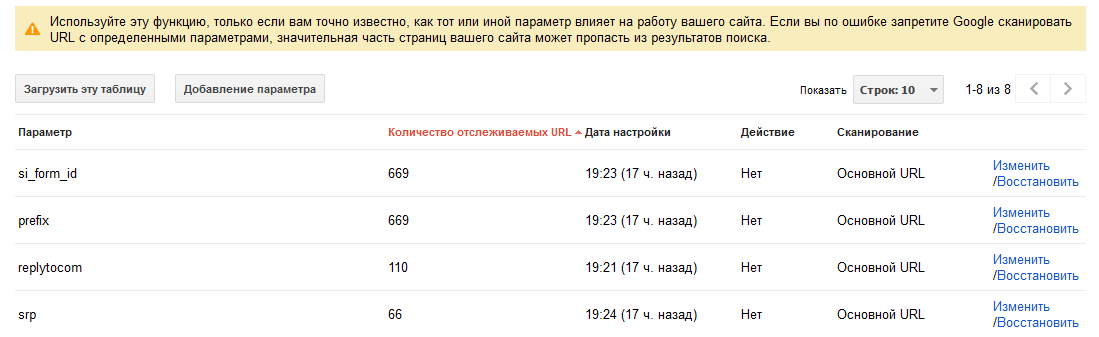
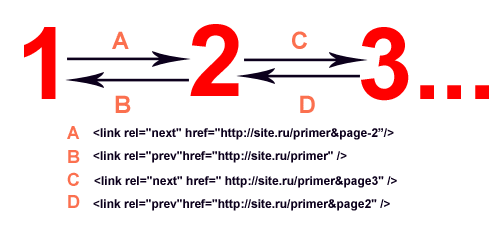
Заходим в Вебмастер> Конфигурация сайта > Параметры URL Тут можно найти список динамических параметров, которые робот Гугла обнаружил на вашем сайте, а также правила их индексирования. По умолчанию Гугл сам решает, индексировать ли ему страницы с динамическими параметрами в адресах (тут не отображается запрещение индексации с помощью других средств, например robots.txt). Индексацию можно запретить, выбрав вариант «Нет», который подразумевает, что добавление параметров к адресу страницы не изменяет ее содержимое, то есть – создает дубликат. В сентябре 2011 года Google ввел rel=Prev и rel=Next, которые призваны помочь вебмастерам справиться с дублированным контентом при наличии страниц с нумерацией. Как и все другие мета данные, эти теги прописываются в <head> страниц. Суть такова: Внешние дубли, в основном, созданы не вебмастерами, но именно им приходится бороться с таким явлением. И вот некоторые способы. В ноябре 2010 года Гугл ввел мета теги атрибута источника. Он применяется для новостей, обзоров, которые часто перепубликовываются на разных сайтах. Выглядит мета тег атрибута источника так: Этот тег проставляется в теге <head> страницы, которая копирует текст, а в content указывается первоисточник. Система та же, что и rel-canonical внутри сайта: дубликат канонизирует первоисточник какого-либо текста, новости. Все знают, что бывает очень сложно заставить воров контента удалить его со своих сайтов. Поэтому можно найти для себя утешение: обратные ссылки с их сайтов, так как многие воры не только оставляют ссылки на ваш сайт в тексте скопированных статей, но и не закрывают их от индексации. Поэтому (ну и не только поэтому, конечно) не забываем делать внутреннюю перелинковку между своими страницами и статьями. Когда страницы-дубликаты «устранены», нужно перестать на них ссылаться как с внешних источников, так и с самого сайта. Если вы поставили 301 редирект (или rel=canonical) – ссылайтесь на страницу, на которую он направлен, чтобы получить максимальный эффект. Запретив индексировать страницу, но ссылаясь на нее с внешних источников, вы передаете поисковикам противоречивые указания, что может вызвать проблемы. Можно просто закрыть глаза на дублированный контент и надеяться, что поисковики сами поймут, что нужно индексировать, а что нет. Это хороший выход, если у вас всего несколько страниц-дубликатов, но это может обернуться неприятностями, если сайт большой и на нем много таких страниц, или если ваш сайт безжалостно копируют. В конечном итоге – решать вам. Что сказать напоследок? Каждый из нас хочет быть уникальным и ни на кого не похожим, чем же наши сайты хуже? Они тоже должны быть единственными в своем роде, так что не копируйте их и другим не позволяйте! И да, подписывайтесь на обновления Блога SEO сектанта!
Борьба с внешними дублями
<meta name="syndication-source"
content="https://primer.ru/pervoistochnik.html">
Напоследок
Если статья была для Вас полезной, не стесняйтесь ссылаться!
 (10 голосов, оценка: 5.00 из 5)
(10 голосов, оценка: 5.00 из 5)Об Авторе
Кристина. SEO-специалист и интернет-маркетолог, не представляющий своей жизни без танцев. Помешана на бижутерии. Постоянно пытается полностью почистить свой почтовый ящик, прочитав все письма. Еще ни разу не удавалось. Также автор блога Marketing Syrup.






{kind=link}
{kind=link}
{kind=link}
Все в точку! Для меня, например, если не использовать сателлиты, то rel=”canonical” и ссылки внутренней перелинковки самое то и можно практически не переживать за отношение ПС к “дублям”, а вот про кросс-доменный rel-canonical я вообще как-то и не слышал.
Влад недавно опубликовал(а)…Настройка кнопки Google +1 (PlusOne)
“Можно просто закрыть глаза на дублированный контент и надеяться, что поисковики сами поймут, что нужно индексировать, а что нет.”
Вот эта рекомендация мне понравилась больше всего!
Но, перед этим, естественно, я достаточно много поработал и кой чего предпринял в этой области.
А потом, глядя насколько переменчивы поисковики в своих поисках на сайте, в особенности Гугл (практически каждый день меняются цифры индексации, притом по неясному алгоритму), отдал всё на их волю: пусть делают, что хотят.
А у меня получился трабл при использовании инструмента удаления УРЛов в Гугл ВМТ. Нашел в том же ВМТ в разделе с ошибками HTML две страницы разделов, к которым были дубли. Дубль был в саом УРЛе, так как в конце ставился флеш (типа domen.com./razdel1/), а по факту на сайте флеша нет в конце. В общем, Гугл воспринимал эти страницы как две разные (с разными датами кеша и ПР). Ну вот я не долго думая и подал заявку на удаление этих двух УРЛов в месте с еще сотней системных дублей. и вот заметил что после выполнения заявки удалились как кривые дубли (со слешем), так и правильные! Печаль!!! И есть правило о 90 днях. Думал что делать, в итоге переименовал разделы и поставил 301 редирект. Вот только поможет ли??? (и вообще, какого черта Гугл удалили обе страницы, если сам же видел их как оригинальную и дубль?)
Леонид, странно, конечно, что со слешем и без Гугл воспринимал как разные адреса. Они-то, конечно, технически дубли, но дело в том, что даже браузеры их склеивают, а ПС и подавно, поэтому и удалил Гугл обе страницы. Вашего случая давно не наблюдала в Гугле.
Тем не менее, поставить 301 редирект с урлов со слешем на урлы без него – это правильно. При этом совершенно не обязательно удалять один из адресов в Вебмастере.
Отличная статья! Большое спасибо автору! Как раз сражаюсь с Пандой от Гугла. Убиваю дубли всеми возможными методами (сейчас вот открыл для себя способ блокировки за параметрами в УРЛ). Буду смотреть что получится.
Такой вот вопрос возник. А нужно ли / как скрывать /скрыть такое: сайт.ру/2012/08??
А то в яндекс вебмастере показывается, что это вот про индексировалось: сайт.ру/2012/08.
То есть как я понимаю архив в индексацию влез?
Простой недавно опубликовал(а)…Город женщин / La Cittа delle donne
Простой, я вас понимаю, у меня тоже такое было. Если ваш сайт на wordpress, можно в плагине “All-in-One SEO pack” поставить галочку, чтобы запрещалась индексация архивов.
Теоритически, можно закрывать по одному, причем если тут есть цифры, то нужно сначала разрешать индексирование страницы со статьей, а потом уже – запрещать индексацию архива. Но это слишком трудозатратно, так что не стоит оно того.
ООоочень полезная статья, разобраны все моменты, на которые возникают вопросы. Удаляю с сайта раздел ( 2000 страниц наверно) =((( это тааааак долго =)
Алексей недавно опубликовал(а)…Ремонт компьютеров на дому, настройка ByFly
Да, долго)) Удачи!
https://promored.ru/2015/ как избавиться от таких дублей?
если вы посмотрите, у меня стоит noindex на таких страницах.