Как найти дубли страниц на сайте
Сегодня я продолжаю тему о дублированном контенте. Вы, конечно, уже прочли мою предыдущую статью о видах дублированного контента, теперь самое время понять, как же искать все эти виды.
Я расскажу и о самых простых способах поиска дублей, для которых не нужно ничего устанавливать, и о некоторых программах и сервисах. Готовы? Поехали!
- Заходим в свой Вебмастер Гугла, потом идем по такому пути: Диагностика> Предложения HTML> и тут вам будут показаны адреса страниц с дублированными (и отсутствующими) мета тегами: заголовками и описаниями.
Для чего это нужно? У страниц-дублей имеются и одинаковые мета данные, и именно таким способом вы сможете их вычислить.
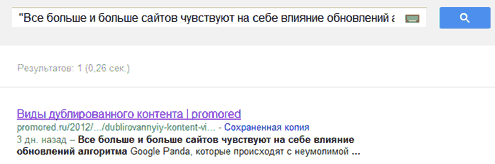
- Используем операторы Google. Во-первых, поиск по точному совпадению. Для этого берем часть текста со страницы (
достаточно одной щепоткизахотелось мне написать, но нет – достаточно одной строчки) и вводим в строку поиска в кавычках. Например:
Если дубли есть – то они вам явятся). Но: чтобы все было в лучшем виде, лучше проверить страницу несколько раз, то есть взять куски текста с разных ее частей. Так результат будет точнее. Я встречала случаи, когда по одному куску текста ничего, кроме проверяемой страницы не находится, а берешь другой – и вот, пожалуйста – целый букет.
Таким способом вы сможете, в основном, искать внешние дубликаты. Чтобы найти внутренние, полные или частичные, нужно искать по куску текста, но в пределах сайта. Тут снова помогут операторы Гугла. Набираем в поисковой строке:
site:vashsite.ru “текст со страницы”
Чтобы проверить статьи внутри блога, лучше всего брать начальные строки (если вы используете тег , конечно, если нет – то без разницы) – так можно узнать, где внутри вашего блога дублируются статьи/части статей и предотвратить остановить это.
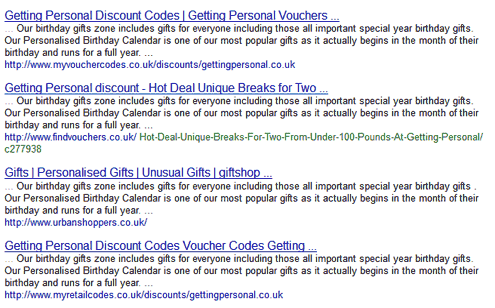
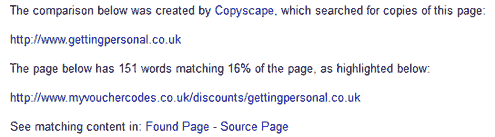
- Онлайн поиск дублей – Copyscape. Этот сервис на английском языке, но разобраться в нем достаточно просто, он очень похож на обычный поисковик. Заходим, вписываем адрес проверяемой страницы и кликаем «Copyscape search». Тут появляются результаты поиска:
Нажимая на каждый результат, можно посмотреть страницу с похожим/идентичным текстом и процент совпадения.
До 30% совпадений – это нормально, ну более-менее. Конечно, все зависит от самого повторяющегося текста: если это календарь на блоге WordPress (а он тоже учитывается) – такое совпадение можно смело игнорировать.
- Mira Tools – тоже онлайн сервис, который покажет уникальность вашего текста, а НЕ страницы, поэтому сюда вводится именно текст (до 3000 символов). Для удобства здесь есть строка «Игнорируемый домен», сюда вводите сайт, текст с которого проверяете, чтобы он не учитывался как дубликат.
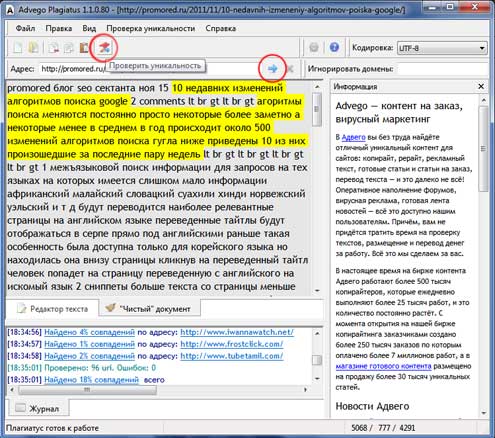
- Теперь о программах для поиска дублей. Сначала Advego Plagiatus, скачать которую бесплатно можно отсюда После скачивания устанавливаем и запускаем. Вводим адрес страницы, которую хотим проверить на уникальность, жмем голубую стрелочку справа и кнопочку «Проверить уникальность» (логично))).
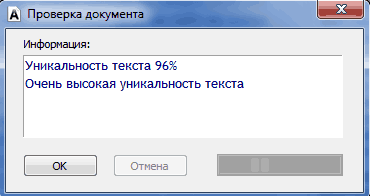
Уникальность считается в процентах, а в конце выдается оценка. Например,
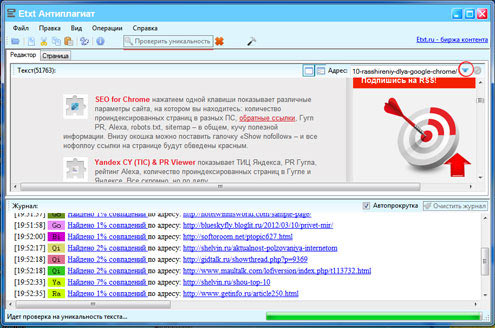
- Следующая программа для проверки уникальности текста – Antiplagiat (можно и онлайн, но нужно регистрироваться). Она похожа на Advego Plagiatus. Сюда тоже нужно ввести адрес проверяемой страницы, нажать на голубую стрелку, а потом на «Проверить уникальность» – и получить результат.
- Есть и другие, косвенные, способы обнаружить, что ваш текст кто-то скопировал. Например, анализ источников посещаемости сайта. Так, я недавно по Метрике нашла, что одну из моих статей (ТОП 10 расширений для Google Chrome, которые сделают вашу работу эффективнее), а точнее, ее половину, скопировали. Спасибо, что хоть со ссылкой на меня с анкором «Далее».
Маленький эксперимент
Я проверила на уникальность свою статью «Одна страница, разные тайтлы» всеми перечисленными мной способами и получила следующие результаты:
- Судя по Вебмастеру, внутренних дублей у меня вообще нет;
- Поиск с операторами Google: статья уникальна;
- Copyscape нашел только одно совпадение на 3% (название моей статьи как анкор ссылки с другого сайта), т.е. уникальность – 97%;
- Miratools – 100% уникальность;
- Advego Plagiatus: 77% уникальности. Часть неуникальна из-за анонса статьи в одном из rss агрегаторов, остальное – 2-6% совпадений по совершенно левым сайтам (даже 100500.tv затесался!);
- Antiplagiat – 89% (и снова же куча левых сайтов, один из них с фильмом «Пункт назначения» – да ладно?!).
Итак, что мы имеем.
- Каждая программа оценивает текст и выдает результат в процентах.
- Поскольку в Miratools текст вводится вручную, то некоторой погрешности можно избежать (не учитывается стандартный текст, характерный для того или иного типа сайта: например, календарь в WordPress )
- Каждый способ по-своему хорош. Но не стоит использовать их все сразу.
- С другой стороны, лучше использовать несколько способов в совокупности.
Лично я для поиска внешних и внутренних дублей использую операторы Google и сервис Copyscape – таким образом можно найти много чего «интересного».
На сегодня все. Не хочется с вами расставаться… и не нужно! Ищите меня в социальных сетях, делитесь этой (и не только этой) статьей с друзьями и подписывайтесь на обновления! Все это особенно полезно, так как в следующих статьях этой серии вы узнаете:
- О том, как бороться с дубликатами
- Об около 20 самых распространенных примерах дублированного контента
Если статья была для Вас полезной, не стесняйтесь ссылаться!
 (18 голосов, оценка: 5.00 из 5)
(18 голосов, оценка: 5.00 из 5)Об Авторе
Кристина. SEO-специалист и интернет-маркетолог, не представляющий своей жизни без танцев. Помешана на бижутерии. Постоянно пытается полностью почистить свой почтовый ящик, прочитав все письма. Еще ни разу не удавалось. Также автор блога Marketing Syrup.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Молодец, Кристюш!
Действительно актуальная и полезная статья. Было интересно читать.
От себя могу добавить что есть еще интересный инструмент, который предоставляет довольно много интересной аналитической информации по сайту и условно бесплатно.
https://сайтрепорт.рф
Бесплатный анализ сайта до 100 страниц. Если страниц больше, то цена за одну страницу варьируется от 0.09 до 0.05 руб за страницу.
По мне так очень удобный сервис.
Спасибо, Дим!
Если кто еще знает какие интересные сервисы – приветствуется указание в комментариях.
Спасибо! Отлично написано. Этим я еще не занималась )
Кристина!
Спасибо за подсказку. Я знал и пользовался только Advego Plagiatus. Но я думаю, что проверить текст ещё и другими способами не помешает. Тем более, что судя по приведённой тобой статистике разница, хоть и небольшая, но есть.
Кристина, Вы не рассмотрели внутренние причины дублирования контента поисковиками, такие как, например, фактор Replytocom.
Дублирование контента из-за ротозейства и невнимательности самого админа, это не такая уж беда и, в общем-то, редкость, а вот, когда сам поисковик его создаёт и индексирует или отказывает по этой причине в индексации, – это проблема. Лично я, ждал, что Вы её будете рассматривать, – это более актуально и необходимо.
Я вообще никакие причины дублирования пока еще не рассматривала, об этом будет в следующих статьях – и именно тогда вы, возможно, измените свою точку зрения по поводу того, что “Дублирование контента из-за ротозейства и невнимательности самого админа, это не такая уж беда и, в общем-то, редкость”, потому что тут я бы поспорила: это не редкость, а наши реалии.
По поводу Replytocom: и об этом будет упомянуто, всему свое время.
P.S. Replytocom создает не поисковик, а сам сайт, поисковику остается только проиндексировать это.
Хороший набор программ, для проверки переделанных текстов, на уникальность. ) Чужие ошибки, в плане копирования чужих текстов и размещение у себя, смысла искать нет. Если только посмотреть, кто любит статьи тырить.
Кристина,помоги разобраться мне с дублями на моём сайте((( Я новичок и никак не соображу что и как((
Виктор, прежде всего вопрос: зачем нужно два одинаковых сайта: btr.pokerfreebie.ru и beltoprent.com? Если каждый из них выполняют свою функцию, они имеют право на жизнь, НО текст-то не должен повторяться.
Это я нашла, использовав поиск по точному совпадению (в кавычках), который описан в статье.
Все когда-то были новичками, в любой сфере. Так что это ваш хороший шанс узнать больше, чем знаете сейчас. Для этого нужна практика, так что сначала сами попробуйте найти дубли с помощью операторов Гугла и Copyscape – все это описано в статье.
На возникшие вопросы отвечу:)
Кристина, помогите, пожалуйста. По Вашему совету нашла в Вебмастере Гугла страницы с одинаковыми заголовками. При переходе по одной из них выдает ошибку 404. Как мне ее найти на блоге и удалить? К примеру- это страницы
/zdorovaya-zhizn/chyornaya-redka.html
/zdorovaya-zhizn/chyornaya-redka
Ульяна, если на страницу, которая выдает 404 ошибку, ссылается какая-нибудь страница сайта, то на нее должен был приходить робот. Так что посмотрите в вебмастере в ошибках сканирования, там обычно фиксируется, какая страница 404 отдает, и какие страницы сайта на нее ссылаются.
Блог один – lifescolours.ru Не понимаю, из-за чего такое получается. Подобная ситуация оказалась и со страницами, у которых одинаковое описание.
Ульяна недавно опубликовал(а)…Жизнь. Что нового?
В этом и проблема – не могу найти страницу, которая ссылается на ту, что выдает ошибку 404. Попробую еще поработать по Вашему совету с плагином Broken Link Checker.
Уважаемая Кристина.Я видел дубль сайта белтопрент на бтр.покерфри,но ума не приложу,откуда он там взялся. И что делать в такой ситуации?Большое спасибо,что обратили внимание на мой крик о помощи
Виктор, попробуйте написать вебмастеру сайта-дубликата. И вообще, меня терзают смутные сомнения, что он был создан теми же людьми или кем-то, знакомым с вашим сайтом. Нужно посмотреть регистрационные данные. Проверьте обязательно.
Привет, Кристина.Сайт с дублем btr.pokerfreebie.ru уничтожен..но в индексе он остался..Как исправить ошибку одного горе-мастера?
КРИСТИНА,как убрать из индекса гугл этот сайт btr,pokerfreebie.ru он уничтожен уже 2 месяца наверно, а в индексе всё как было так и осталось
Виктор, сейчас с данного сайта стоит 302 редирект на optimus.timeweb.ru/error_domain.htm. 302 редирект ВРЕМЕННЫЙ, он не склеивает домены, именно поэтому тот сайт не удаляется из индекса (в кэше его нет.) Поэтому 1. Ставим 301 редирект, 2. вручную удаляем страницы из индекса в Вебмастере Гугл (для верности). Возможно, вам также будет интересно почитать: https://support.google.com/webmasters/bin/answer.py?hl=ru&answer=1663427
Кристина, а мне очень интересен ваш ответ на такой вопрос:
как вы относитесь к двум битым ссылкам, 55 одинаковых Title на вашем сайте? (могу дать адреса страниц с ошибками…)
И еще вопрос: почему вы не проводите верификацию домена?
Приглашаю на свой блог, надеюсь на взаимные комменты и сотрудничество.
Здравствуйте, Сергей. Отвечаю на ваши вопросы.
2 битые ссылки: если посмотреть внимательнее, то ссылок таких намного больше. Парочка на удаленный тег в категориях, которые закрыты от индексации, еще несколько – в комментарих в сайтах комментаторов, их удалять не вижу смысла. Я переодически проверяю сайт на наличие 404 ошибок, чтобы исправить их. Если у вас есть пример 404 на странице, которая ранжируется в ПС, и не в комментариях, укажите – исправлю. Я таких не наблюдаю.
Про одинаковые тайтлы: у всех страниц (статьи, категории, контакты…), которые индексируются, тайтлы уникальны. Дублированные тайтлы тоже есть (заметьте, не 55, а намного больше), они наблюдаются у странц с replycom, которые генерируются автоматически после каждого комментария. Если посмотрите, то станет ясно, что они закрыты от индексации, тк являются дублями.
Домен: он мне достался с курсов, а не покупался лично мной. Так что тут есть свои подводные камни, не буду вдаваться в подробности.
Также советую https://сайтрепорт.рф очень полезный сервис.. Они увеличили бесплатный лимит до 250 страниц.
спасибо, Игорь)