Аудит сайта за 15 минут с Screaming Frog SEO Spider
Привет всем! SEO сектант снова в строю, а это значит, что я готова рассказать много чего интересного! И сегодня немного об аудите сайта и его важности.
{kind=link}
Как бы хорошо ни шли дела по продвижению, сайт все равно нужно периодически проверять на наличие различных ошибок, которые мешают ему ранжироваться еще выше. А если сайт не очень хорошо продвигается – тогда такой анализ важен вдвойне.
Сайт можно анализировать кропотливо и детально – это лучше делать на первом этапе работы, а также раз в полгода, например. Все зависит от самого сайта, его структуры, темпов развития и т.д. Намного чаще можно делать экспресс-аудиты. Говоря экспресс-аудит, я ни в коем случае не имею в виду плохое его качество. Даже наоборот: он должен быть достаточно высокого качества, чтобы помочь выявить все существующие и потенциальные недочеты и сдерживающие продвижение факторы.
Экспресс-аудит можно провести с помощью программы Screaming Frog SEO Spider. Бесплатную ее версию можно скачать отсюда. Как это принято среди бесплатных версий, функционал и количество проверяемых страниц ограничено (500 страниц), но в большинстве случаев этого вполне достаточно.
Итак, открываем программу и вводим сверху URL главной страницы сайта, который будем проверять.
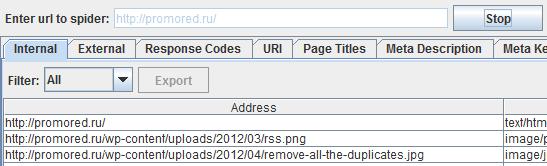{kind=link}
Нажимаем на “Start”, и программа начинает парсить все адреса страниц сайта, отображая много полезной информации по каждой из них. Сюда включены и адреса картинок, и различных файлов, если они есть на вашем сайте. Чтобы убрать лишнюю информацию, можно просто отсортировать адреса страниц по типу.
{kind=link}
Для удобства вся информация разбита на вкладки, переключать которые можно сверху. Итак, немного о вкладках и о том, что они помогут понять о сайте.
Internal (внутренние ссылки) – первая вкладка с основной информацией о страницах сайта, выше шла речь именно о ней. Она разбита на колонки, которые можно отсортировать по алфавиту (для цифр – от большей к меньшей, и наоборот) одним нажатием на название столбца.
{kind=link}
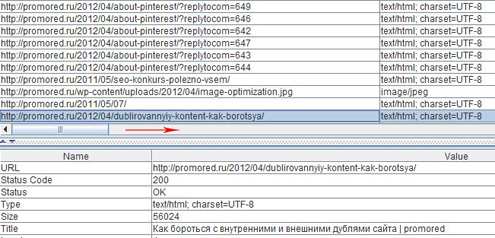{kind=link}
Выделив одну строку, в нижнем блоке вы увидите информацию по данной странице сайта (информация об адресе страницы, внутренних входящих/исходящих ссылках, картинках). Уже на этом этапе можно увидеть потенциальные проблемы сайта, но мы идем дальше, так как на остальных вкладках все это будет отображено подробнее.
External (внешние ссылки) – список ресурсов, на которые с вашего сайта стоят открытые ссылки.
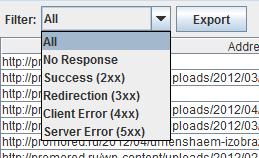
Response Codes – показывает HTTP заголовки страниц. Я обычно сортирую их по убыванию (нажав на название столбца), таким образом, сверху остаются 5XX, 4XX, 3XX, и только потом 200.
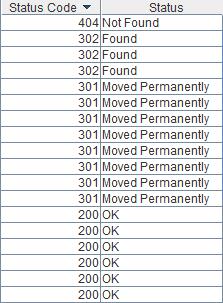{kind=link}
Вот на первые три типа стоит обратить особое внимание. Для дальнейшего анализа и составления отчета их можно экспортировать в Excel (формат csv) вместе или по отдельности (такая функция есть на каждой вкладке).
{kind=link}
URl (проблемные адреса страниц) – тут собраны проблемные адреса сайта:
- С символами, не находящимися в ASCII.
- С нижними подчеркиваниями (это, конечно, не считается нарушением правил ПС, но все-таки использование дефисов «-» в адресах предпочтительнее, так как они разделяют слова, а нижние подчеркивания – нет)
- С заглавными буквами (в статье о распространенных примерах дублированного контента я писала, что адреса типа site.ru/primer и site.ru/Primer считаются дублями)
- Дублированные страницы – тут, в принципе, все понятно: война дублям!
- Динамические адреса – их на сайте лучше не использовать, потому что они, во-первых, не дружественные, а во-вторых – создают дублированный контент.
- Адреса страниц длиной более 115 символов – чем короче адрес, тем лучше и понятнее, поэтому лучше не превышать 115 символов в адресе. Например, вот такой адрес уж точно не выглядит привлекательно: site.ru/povest-o-tom-kak-possorilsya-ivan-ivanovich-s-ivanom-nikifoovichem-a-potom-ne-hotel-s-nim-miritsya-gogol-kratkoe-soderzshanie.
Page Titles (Тайтлы страниц) – крайне полезная вкладка с Тайтлами страниц и информацией о них. Здесь можно найти:
- Страницы, где нет тайтлов. Если эти страницы важны для продвижения, тайтлы нужно добавить обязательно.
- Страницы с одинаковыми тайтлами. Правило: заголовки должны быть у-ни-каль-на-ми. Кстати, очень часто тайтлы бывают одинаковыми у страниц-дубликатов, поэтому список страниц с одинаковыми тайтлами – один из ключей к поиску дублей на сайте.
- Тайтлы, длиннее 70 символов. До недавнего времени общепринятая длина тайтла (для Гугла) составляла 60-70 символов. Но, похоже, что теперь заголовок измеряется не в символах, а в пикселях. К такому выводу пришли западные seoшники, которые протестировали тайтлы, состоящие из широких букв (вместилось всего 45) и узких букв (вместилось 107 (!) символов). Подробнее об эксперименте можно почитать здесь (на английском).
- Страницы, где тайтлы совпадают с H1 заголовками. Такого быть не должно, так как каждый из этих элементов страницы выполняет свою роль в оптимизации страницы под определенные запросы. Конечно, H1 и Тайтл связаны одной темой, но раскрывать ее они должны с разных сторон. К сожалению, на некоторых CMS тайтл автоматически берется из заголовка H1, тут уже вопросы к разработчикам.
Meta Description (мета-описание) – информация о мета теге Description, а также его длина, список страниц с повторяющимися или отсутствующими мета описаниями.
Meta Keywords – что тут скажешь, их лучше не прописывать. Эту вкладку можно пропустить.
H1 – все заголовки H1, хотя лучше, конечно, чтобы на каждой странице было по одному такому заголовку (что не всегда выходит из-за конфигурации CMS).
H2 – все заголовки H2 на каждой странице.
Images – список картинок сайта и их вес. Полезно для анализа и потенциальных возможностей увеличения скорости загрузки сайта за счет оптимизации картинок.
Meta&Canonical – эта вкладка очень важна, так как она показывает meta robots и rel=canonical на страницах.
Изучив все данные этих вкладок, мы можем сохранить их в Excel файле и уже на основе полученной информации определить слабые места сайта и избавиться от них.
Screaming Frog поможет получить всю основную информацию о сайте, проанализировать его структуру, мета данные, заголовки и даже найти дубли контента. Разобраться в ней достаточно легко, и после этого анализ сайта будет занимать не больше 15 минут. И не забудьте после проделанной работы найти время посмеяться над забавными случаями в жизни сеошника))
Удачи всем читателям promoRED. И да, не забываем подписываться на обновления.
Если статья была для Вас полезной, не стесняйтесь ссылаться!

 (13 голосов, оценка: 4.85 из 5)
(13 голосов, оценка: 4.85 из 5)Об Авторе
Кристина. SEO-специалист и интернет-маркетолог, не представляющий своей жизни без танцев. Помешана на бижутерии. Постоянно пытается полностью почистить свой почтовый ящик, прочитав все письма. Еще ни разу не удавалось. Также автор блога Marketing Syrup.
Ответить на Кристина Отмена ответа
-
 Про SEO, PPC и Кленовом листе
Про SEO, PPC и Кленовом листе
-
 Предпраздничные рекламные кампании: как правильно отслеживать с помощью UTM тегов
Предпраздничные рекламные кампании: как правильно отслеживать с помощью UTM тегов
-
 Googlebot не может получить доступ к файлам CSS и JS. Что делать?
Googlebot не может получить доступ к файлам CSS и JS. Что делать?
-
 Источники трафика в Google Analytics: кто главнее?
Источники трафика в Google Analytics: кто главнее?
-
 Полезные Excel формулы и функции для SEO
Полезные Excel формулы и функции для SEO
-
 Как добавить внешнюю ссылку в аннотацию видео на YouTube
Как добавить внешнюю ссылку в аннотацию видео на YouTube
Кристина, спасибо – отличное пособие по Screaming Frog SEO Spider! Очень полезно особенно для тех, кто вообще не знаком с этой программой.
Влад недавно опубликовал(а)…Использование директив файла .htaccess — часть вторая
Я пару раз пробовал запустить у себя эту программу, к сожалению компьютер думал иначе. Я анализирую Xenu и иногда подключаю SiteVerify.
V_Koktebel недавно опубликовал(а)…Фото и видео с набережной Коктебеля
Замечательное пособие! Но об фразу “Meta Keywords – что тут скажешь, их лучше не прописывать.” просто споткнулась. Может роботам она и не нужна, а вебмастеру просто необходима. Так вы не забудете какую страницу под какой запрос оптимизируете.
Светлана, ну это спорный вопрос. Если долго работать над сайтом, то можно запомнить, какая страница под какой запрос подточена (по крайней мере, я хорошо запоминаю это на сайтах клиентов). Даже без запоминания это видно по Тайтлу (если он, конечно, толковый), так что я бы все же не ставила на meta keywords
Кристи просто умница – по порядку и не торопясь расписала, что не пришлось дядям разбираться-мучиться с буржуйским софтом. Спасибо!
Gooper недавно опубликовал(а)…Цены в Черногории и интервью с мигрантом из России
Пожалуйста! Пользуйтесь
Кристина, большое спасибо за вашу работу. Очень полезный блог.
Если можно, небольшой вопрос: в программе по кнопке Images не отображаются картинки с сайта, в чем может быть проблема?
Спасибо.
Рада, что помогла вам, Олег)
А что значит не отображаются картинки? Там ссылки на них должны быть + размер указан. Вы имеете ввиду эта информация не отображается?
Вообще вкладка Images серым цветом без каких-либо данных.
У меня небольшой интернет-магазин, недавно увидел, что Гугл не видит картинок, благодаря вам начал прописывать ALT и Title для изображений.
Но вото, почему Screaming Frog SEO Spider не видит информации о картинках мне непонятно, причем Image info информацию показывает, а Images, вообще ничего.
А скажите пож-та, почему у меня при проверке сайта – я забиваю адрес сайта, а он кроме главной никакие не парсит…почему? Значит и роботу поисковиков не перейти? Помогите пож-та. сайт – bcinform.ru
Если еще актуально, то отвечу.
Ваш сайт проиндексирован вполне нормально. Паук парсит страницы, я проверяла)
В качестве бесплатного аналога, посмотрите в сторону netpeak spider
Дмитрий недавно опубликовал(а)…Не удалось получить ppa 404 Not Found
Знаю ее. Но screaming frog мне нравится больше. Тем более, те возможности, которые я описала, тоже бесплатны)
не могу с помощью Screaming Frog SEO Spider проверить сайт, т.к. после ввода URL и старта в Status выдается сообщение “Connection Refused”. В чём причина, что делать?
Судя по всему, Паук пытается слишком быстро загружать адреса страниц. В бесплатной версии Вы не можете уменьшить скорость, так что просто попробуйте еще раз. И попробуйте еще другие сайты проверить, посмотрите, что будет там. Вот ответ у них в FAQ по этому поводу.
Если ошибка сохранится, можете скинуть мне адрес своего сайта, я попробую проверить у себя.
“Страницы, где тайтлы совпадают с H1 заголовками. Такого быть не должно, так как каждый из этих элементов страницы выполняет свою роль в оптимизации страницы под определенные запросы.”
как же так, когда сам яндекс в своём руководстве советует использовать одни и те же ключевики в h1 и тайтле? Да и что за логика, страницу описать разными тегами….если объект страницы можно точно описать одними и теми же словами, со стороны поисковиков было бы глупо разрешать их в одном теге и “не одобрять” в другом
Игорь, Вы, видимо не совсем меня поняли. Объясню по-другому, на примере моей недавней статьи.
Тайтл совпадает с H1 Заголовком:
Тайтл: Как узнать, что пользователи ищут на Вашем сайте?
H1: Как узнать, что пользователи ищут на Вашем сайте?
В данном случае оба тега совпадают, т.е. идентичны, вот это не хорошо, т.к. вариации ключевых слов не используются.
Тайтл и H1 не совпадают:
Тайтл: Пользовательский поиск: что пользователи ищут на сайте?
H1: Как узнать, что пользователи ищут на Вашем сайте?
В данном случае используются вариации одних и тех же слов.
То, что ПС одобряют ключевики в одних тегах и не одобряют в других – нонсенс.
Прочитайте про тайтл и h1 https://help.yandex.ru/webmaster/search-results/quick-links.xml#marking
Спасибо, за ликбез, конечно.
Меня поражает такая подмена понятий. Мне кажется, вы даже не потрудились прочесть мою статьи и мой предыдущий комментарий, раз даете мне ссылку на то, как помочь Яндексу подобрать быстрые ссылки. Серьезно? Вы ухватились за малую частность в хелпе Яндекса и пытаетесь применить это правило в общем, даже не желая вникать.
Если уже речь пошла о быстрых ссылках, то я сомневаюсь, что вы будете пытаться сделать быстрые ссылки для каждой страницы своего сайта знакомств, не так ли? Чаще всего в быстрые ссылки добавляются общие страницы, которые и не участвуют в основном продвижении (контакты, например). Еще вы можете провести маленький эксперимент: найти несколько сайтов с быстрыми ссылками и проверить, действительно ли заголовки на страницах (не обязательно h1 заголовки, Яндекс же дает этот тег как пример, правда?) полностью совпадают с тайтлами страниц и анкорами быстрых ссылок.
а как сохранять и мпортировать результат?
Сохранить через File > Save можно только в платной версии. Но экспортировать можно и в бесплатной через опцию меню Advanced Export
Кристина, Добрый день! Почему лучше не прописывать: “Meta Keywords – что тут скажешь, их лучше не прописывать. Эту вкладку можно пропустить.”?
Просто везде разная информация, касательно данного вопроса.
Заранее спасибо тебе за ответ:)
Anastasiia недавно опубликовал(а)…—50% на программный комплекс «Гранд-Смета»!
Можете смело “забить” на Meta Keywords, оптимизаторы очень злоупотребляли ими, поэтому ПС уже давно и успешно игнорируют этот тег. Сейчас он может служить только дополнительной подсказкой для конкурентов.
Кристина, помогите. Мне друзья пишут , что проблема у меня с title. Я сама не могу разобраться. Я установила недавно шаблон новый. Так, как сайт перед Новым 2015 годом попал под АГС. Все получилось из за дудлей страниц. С этим справилась. И вот теперь с шаблоном. Я посмотрела код страницы и вижу , что title моих статей не заключен в тег ни , ни , как поправить. Буду очень благодарна.
Рита недавно опубликовал(а)…Форум блогеры круглого стола приглашает
Здравствуйте. А я вижу, что тайтл у вас в правильном теге.
В любом случае, я не специализируюсь на правке шаблонов WP. Более того, думаю, вы сами можете справиться, раз уж предлагаете услуги по созданию WP сайта, что в моем понимании требует хотя бы минимальных знаний о шаблонах, их использовании и правке кода.
Здравствуйте Кристина! Талант есть талант+ интерес по теме ну и подача материала. Просто выражаю восхищение Автору. С уважением.
Благодарю!
Кристина, помогите советом, пожалуйста. ЛЯгушка не хочет парсить сайт [удалено ажминистратором]. Выдает Connection Refused и ответ 0. По ссылке на FAQ ходила, варианты User Agent перебирала – ни с каким парсить не хочет. Сайт для меня новый, только взяла его, что может быть не так с ним?
Не знаю даже. Может, у вас стоят настройки кроулера какие-то.
Я попробовала, у меня все парсится. Очень много 301вых и канониклов. Из-за https/http, в основном.